IT运维服务体系的构建,应遵循“易使用、易汇总、易管理”的原则,依次解决客观存在的问题,从而最大限度地推动IT运维服务体系的建设进程。该体系涵盖了运维服务制度、流程、组织、队伍、技术服务平台以及运行维护对象等多个方面,涵盖了制度、人员、技术和对象四大关键因素。
运维制度不仅为运维管理工作提供了规范保障,还是流程构建的基石。在运维服务组织中,相关人员需遵循制度规定和标准化的工作流程,借助先进的运维管理平台,对各类运维对象进行系统化、规范化的运行管理和技术操作。
IT故障定位是诊断故障直接原因或根本原因的关键环节,它直接影响到故障恢复的效率。虽然故障定位往往是整个故障处理过程中耗时最长的部分,但其核心目标是在最短的时间内恢复系统,而非深入探究问题的根源,后者通常由问题管理模块负责。在实际操作中,大部分可用性故障可以通过运维专家的经验假设或已知预案来解决,但仍有部分故障,特别是性能、应用逻辑或数据故障,需要多方面的协同工作和专业工具的支持。
在数据中心环境中,技术运维人员通常对已知故障具有敏锐的洞察力,能够根据自身经验迅速找到问题的根源。而资深专家则能通过深入理解系统的内在原理,从普遍的故障现象中推测出可能的原因。作为运维技术专家,准确判断故障诊断路径的能力至关重要,这种能力往往需要大量的运维案例积累和实践锻炼。同时,准确的数据采集也是一项需要深厚运维知识支撑的技能。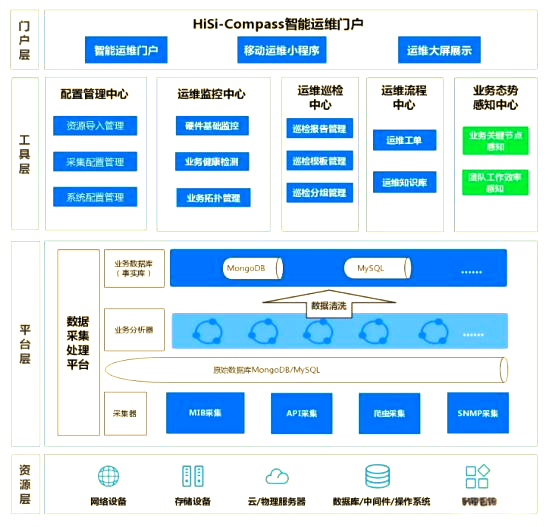
例如,在进行故障分析时,我们可能需要关注CPU资源的使用情况。那么,如何采集相关数据呢?是简单地查找某段时间内CPU使用率的平均值,还是需要关注最高阈值?当CPU使用率达到100%时,是否就意味着一定存在问题?实际上,问题的复杂性远超于此。CPU偶尔出现的尖峰使用率大多数情况下是无害的,不会对系统造成实质性影响。只有当CPU长期处于高使用率状态,才可能面临资源不足的困境,进而影响系统的整体性能。
一、运维处理原则
在IT系统的日常运行中,遇到问题或故障是不可避免的。针对这些情况,我们总结出了两个基本的处理原则:
首先,所有采取的措施或方法都必须以迅速恢复业务运行作为首要任务。这意味着在面对系统故障时,我们必须迅速而有效地作出反应,以确保业务的连续性不受影响。
其次,对于系统中的BUG或兼容性问题,我们需要及时进行升级和优化。通过升级系统版本或优化相关配置,我们可以确保系统的稳定性和性能得到持续提升,从而更好地满足业务需求。
1.1. 恢复业务优先
在IT系统运维中,恢复业务优先意味着,无论遇到何种故障或问题,首要任务都是迅速恢复业务运行。这并不意味着忽视问题根源的查找,而是在面对紧迫的业务连续性需求时,采取的一种紧急应对策略。下面,我们将通过一个简单的例子来阐释这一原则。
假设在应用A和B的系统联调过程中出现失败,我们该如何行动?此时,恢复业务优先的策略可以这样实施:
(1)首先尝试从A应用的服务器去ping B应用的网络,确认端口和网络连通性。如果连通,那么直接在A服务器上绑定B服务器的hosts,以绕过可能的问题环节。
(2)进一步排查问题,梳理A到B之间可能经过的各个环节,找到并解决出现问题的环节,比如HA连接异常,通过重启或扩容来恢复。
通常情况下,第一种方法能够迅速见效,尤其是在A和B之间不存在跨机房访问的情况下。尽管这种做法可能在一定程度上破坏了A到B之间的架构平衡,但它能迅速恢复业务运行,满足我们的首要任务。
1.2. 及时升级与反馈
在IT系统运维中,及时升级与反馈是至关重要的。由于故障的影响往往难以预先准确判断,因此,一旦发生故障,应立即向领导汇报,以确保其能及时掌握第一手信息,并协调相关资源进行处理。特别是对于那些对业务影响重大的严重及以上告警故障,如网银交易系统故障或主机CPU超出阈值等,必须迅速上报,以便迅速采取应对措施。
2. 当业务指标出现明显波动,如双11或618促销、国庆或重要节假日等时段,这通常意味着系统承受着额外的压力;
3. 故障处理所需时间明显超出预期(参考故障处理时效标准);
4. 安全升级包、设备或方案已由厂家进行重大升级,这可能引入新的风险或需要特别关注;
5. 系统性问题已受到监控中心或关联系统的关注,且该故障对其产生了实质性影响。

二、运维策略
在制定全面的运维计划时,我们需明确服务标准,并围绕现场软硬件巡检这一核心任务,强化计划的执行力度。数据中心等关键基础设施的运维工作,通常涉及分项工作计划、时间维度计划等的制定,以及按流程、按计划的实施与保障。现场巡检不仅对于发现系统薄弱环节、关键业务节点和潜在隐患至关重要,还是制定应急预案及备品备件计划的关键环节。在执行运维计划过程中,我们必须严格遵循流程规范,注重风险控制,并定期向用户反馈执行情况。同时,签订售后服务承诺函与客户约定服务级别,确保所提供的资源和方案严格按约定执行。
三、运维处理方法论
在云时代,IBM提出了一种新的运维方法论,即CSMO(Cloud Service Management and Operations)。这一方法论源于四个关键方面:
第一,ITIL特别是ITIL 4,作为国际IT服务标准的新时代里程碑,不仅继承了ITIL V3的精髓,更融入了对DevOps等新兴技术的支持。
其次,敏态IT运维方法论SRE(Site Reliability Engineering,站点可靠性工程)的崛起,为互联网及公有云环境下的运维服务提供了全新的视角。
第三,Infrastructure as a Code的理念与实践,将基础设施自动化、运维全球最佳实践以及丰富案例紧密结合,推动了运维方式的革新。
第四,强化运维与开发的协同效应,成为提升IT服务管理效能的关键举措,通过将组织、文化、流程与DevOps深度融合,实现了业务连续性的新飞跃。
在运行维护服务的范畴内,涵盖了信息系统各组件的运行维护与安全防范。这不仅保障了用户信息系统的稳定运行,还通过数据分析与记录,为用户提供全面的系统建设规划建议,助力其信息化发展的稳健前行。
用户信息系统的构建要素包括硬件设备和软件系统。其中,硬件设备如网络设备、安全设备等是信息系统的基石;而软件系统则包括操作系统、数据库软件等,它们共同构成了信息系统的核心功能。
当信息系统出现故障时,运维处理通常遵循三个阶段:故障前定位分析、故障中处理过程以及故障后总结。其中,隔离、重启和降级是恢复业务的关键方法。隔离策略旨在将故障对象从集群中移除,确保其不再提供服务,常采用的方法包括调整上游权重为零或直接停止故障对象的服务。通过这些措施,可以有效地降低故障影响范围,保障业务连续性。
通过绑定hosts或配置路由的方式,可以巧妙地绕开故障对象,例如,利用智能路由管理域关闭特定线路。但在此过程中,需格外警惕雪崩效应的发生。
重启策略包括服务重启和服务器重启(操作系统重启),它是在故障处理中的关键环节。重启的顺序通常遵循:故障对象、故障对象上游、故障对象下游,且重启顺序与故障对象距离越远,顺序越靠后。
降级措施旨在预防更大的故障,但可能会对业务产生一定影响。它需要与业务研发团队紧密合作,共同制定和实施预案。在项目规划和核心应用组件设计中,应充分考虑可能出现的重大故障及其应对措施。
此外,重启和隔离操作有一个重要前提,即对象必须是无状态的或幂等的。在生产环境中,对象状态应尽可能简洁明确:大多数对象应保持无状态,少量特殊情况可设置为临时有状态或真正有状态。
从故障影响方的角度看,运维故障处理涉及多个内部和外部组织架构。在处理过程中,需要信息传递者、故障定位者和故障处理者三类角色协同工作,以确保故障能迅速、有效地得到解决。
他们的核心使命是迅速恢复业务运行。在IT运维系统中,这三类角色通常不会同时出现。例如,在凌晨值班时,可能只需故障处理者负责应对,而在业务恢复后,故障定位者会在第二天介入,深入挖掘故障根源并寻求优化措施。
此外,故障发生后,影响方主要分为两大类:
内部用户
这包括内部应用自身的调用问题以及内部使用人员发现的问题。其处理方法与外部用户相似。外部用户
处理外部用户的问题较为复杂。关键在于如何将外部用户的问题转化为内部用户的问题进行处理。例如,当供应商无法访问公司网站时,应首先尝试在本地模拟问题是否可重现。若能重现,则问题可能出在内部系统上,需作为内部用户问题来处理;若不能重现,则需进一步邀请其他内部用户模拟问题,并排查是否为自身环境问题。同时,建议外部用户尝试hosts绑定到其他入口,以排除DNS和外部链路问题。若绑定后访问正常,则可初步判断为外部问题,并着手恢复业务。
若上述方法均无法解决问题,则需收集外部用户的必要信息,如出口IP和客户端版本等,以便进行处理。在此过程中,建议使用标准化的信息收集模板,以减少沟通成本和时间浪费。